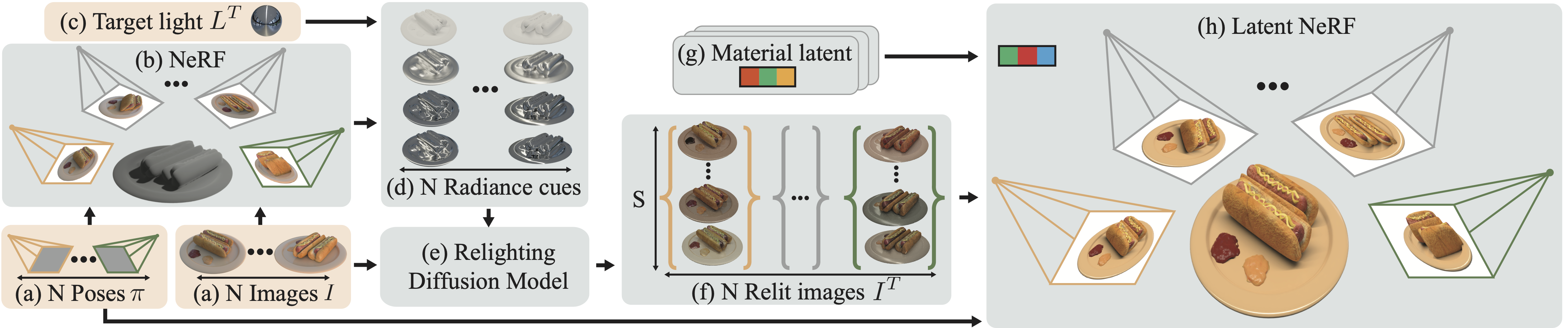
Existing methods for relightable view synthesis --- using a set of images of an object under unknown lighting to recover a 3D representation that can be rendered from novel viewpoints under a target illumination --- are based on inverse rendering,
and attempt to disentangle the object geometry, materials, and lighting that explain the input images.
Furthermore, this typically involves optimization through differentiable Monte Carlo rendering, which is brittle and computationally-expensive.
In this work, we propose a simpler approach: we first relight each input image using an image diffusion model conditioned on lighting and then reconstruct a Neural Radiance Field (NeRF) with these relit images,
from which we render novel views under the target lighting. We demonstrate that this strategy is surprisingly competitive and achieves state-of-the-art results on multiple relighting benchmarks.